



The smallest vector index in the world. RAG Everything with LEANN!
LEANN is a revolutionary vector database that democratizes personal AI. Transform your laptop into a powerful RAG system that can index and search through millions of documents while using **97% less storage** than traditional solutions **without accuracy loss**.
LEANN achieves this through *graph-based selective recomputation* with *high-degree preserving pruning*, computing embeddings on-demand instead of storing them all. [Illustration Fig →](#️-architecture--how-it-works) | [Paper →](https://arxiv.org/abs/2506.08276)
**Ready to RAG Everything?** Transform your laptop into a personal AI assistant that can search your **[file system](#-personal-data-manager-process-any-documents-pdf-txt-md)**, **[emails](#-your-personal-email-secretary-rag-on-apple-mail)**, **[browser history](#-time-machine-for-the-web-rag-your-entire-browser-history)**, **[chat history](#-wechat-detective-unlock-your-golden-memories)**, or external knowledge bases (i.e., 60M documents) - all on your laptop, with zero cloud costs and complete privacy.
## Why LEANN?
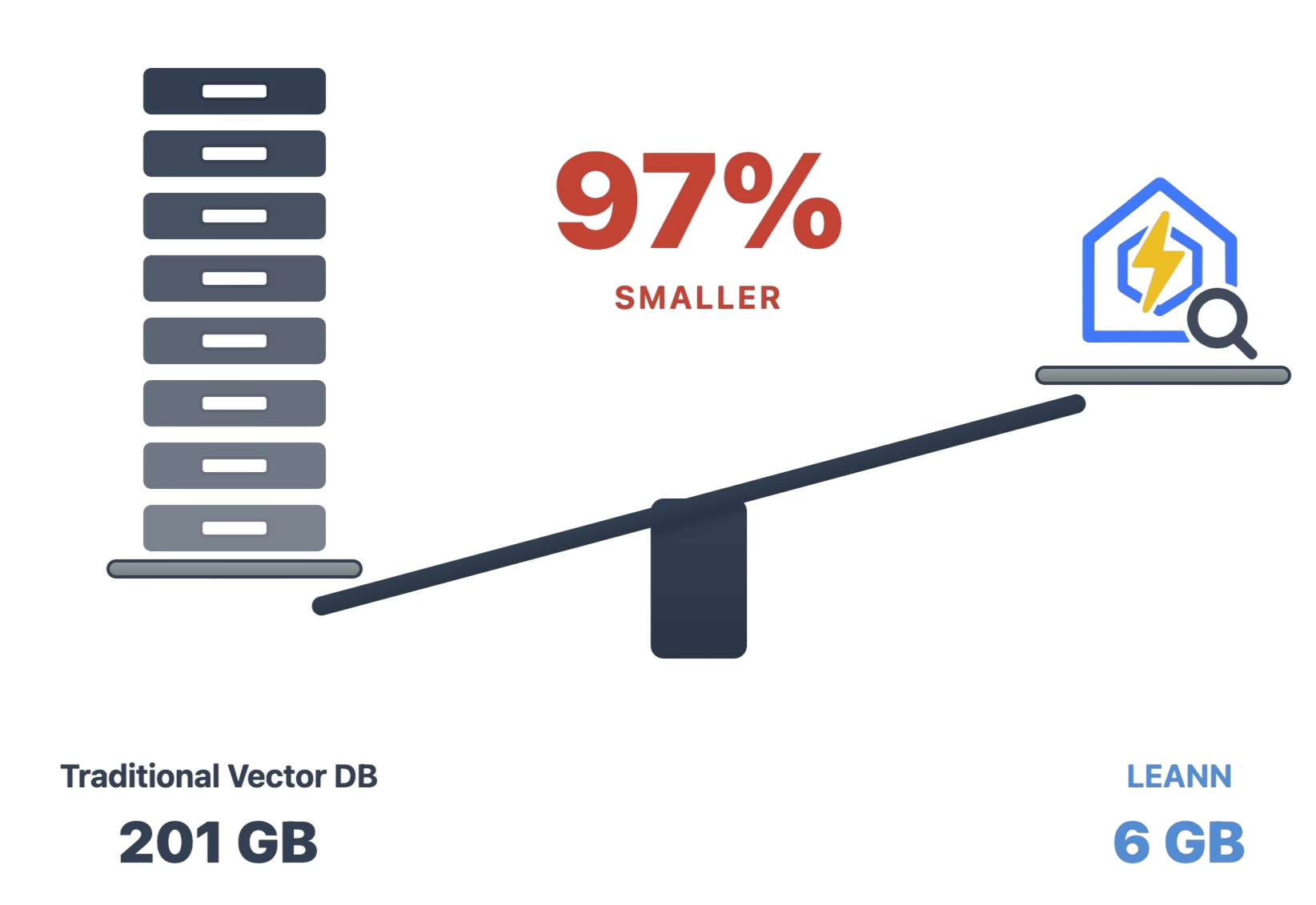
> **The numbers speak for themselves:** Index 60 million Wikipedia chunks in just 6GB instead of 201GB. From emails to browser history, everything fits on your laptop. [See detailed benchmarks for different applications below ↓](#storage-comparison)
🔒 **Privacy:** Your data never leaves your laptop. No OpenAI, no cloud, no "terms of service".
🪶 **Lightweight:** Graph-based recomputation eliminates heavy embedding storage, while smart graph pruning and CSR format minimize graph storage overhead. Always less storage, less memory usage!
📈 **Scalability:** Handle messy personal data that would crash traditional vector DBs, easily managing your growing personalized data and agent generated memory!
✨ **No Accuracy Loss:** Maintain the same search quality as heavyweight solutions while using 97% less storage.
## Installation
> `pip leann` coming soon!
```bash
git clone git@github.com:yichuan-w/LEANN.git leann
cd leann
git submodule update --init --recursive
```
**macOS:**
```bash
brew install llvm libomp boost protobuf zeromq pkgconf
# Install with HNSW backend (default, recommended for most users)
# Install uv first if you don't have it:
# curl -LsSf https://astral.sh/uv/install.sh | sh
# See: https://docs.astral.sh/uv/getting-started/installation/#installation-methods
CC=$(brew --prefix llvm)/bin/clang CXX=$(brew --prefix llvm)/bin/clang++ uv sync
```
**Linux:**
```bash
sudo apt-get install libomp-dev libboost-all-dev protobuf-compiler libabsl-dev libmkl-full-dev libaio-dev libzmq3-dev
# Install with HNSW backend (default, recommended for most users)
uv sync
```
**Ollama Setup (Recommended for full privacy):**
> *You can skip this installation if you only want to use OpenAI API for generation.*
**macOS:**
First, [download Ollama for macOS](https://ollama.com/download/mac).
```bash
# Pull a lightweight model (recommended for consumer hardware)
ollama pull llama3.2:1b
```
**Linux:**
```bash
# Install Ollama
curl -fsSL https://ollama.ai/install.sh | sh
# Start Ollama service manually
ollama serve &
# Pull a lightweight model (recommended for consumer hardware)
ollama pull llama3.2:1b
```
## Quick Start in 30s
Our declarative API makes RAG as easy as writing a config file.
[Try in this ipynb file →](demo.ipynb) [](https://colab.research.google.com/github/yichuan-w/LEANN/blob/main/demo.ipynb)
```python
from leann.api import LeannBuilder, LeannSearcher, LeannChat
# 1. Build the index (no embeddings stored!)
builder = LeannBuilder(backend_name="hnsw")
builder.add_text("C# is a powerful programming language")
builder.add_text("Python is a powerful programming language and it is very popular")
builder.add_text("Machine learning transforms industries")
builder.add_text("Neural networks process complex data")
builder.add_text("Leann is a great storage saving engine for RAG on your MacBook")
builder.build_index("knowledge.leann")
# 2. Search with real-time embeddings
searcher = LeannSearcher("knowledge.leann")
results = searcher.search("programming languages", top_k=2)
# 3. Chat with LEANN using retrieved results
llm_config = {
"type": "ollama",
"model": "llama3.2:1b"
}
chat = LeannChat(index_path="knowledge.leann", llm_config=llm_config)
response = chat.ask(
"Compare the two retrieved programming languages and say which one is more popular today.",
top_k=2,
)
```
## RAG on Everything!
LEANN supports RAG on various data sources including documents (.pdf, .txt, .md), Apple Mail, Google Search History, WeChat, and more.
### 📄 Personal Data Manager: Process Any Documents (.pdf, .txt, .md)!
Ask questions directly about your personal PDFs, documents, and any directory containing your files!

The example below asks a question about summarizing two papers (uses default data in `examples/data`):
```bash
# Drop your PDFs, .txt, .md files into examples/data/
uv run ./examples/main_cli_example.py
```
```
# Or use python directly
source .venv/bin/activate
python ./examples/main_cli_example.py
```
### 📧 Your Personal Email Secretary: RAG on Apple Mail!

**Note:** You need to grant full disk access to your terminal/VS Code in System Preferences → Privacy & Security → Full Disk Access.
```bash
python examples/mail_reader_leann.py --query "What's the food I ordered by doordash or Uber eat mostly?"
```
**780K email chunks → 78MB storage** Finally, search your email like you search Google.
📋 Click to expand: Command Examples
```bash
# Use default mail path (works for most macOS setups)
python examples/mail_reader_leann.py
# Run with custom index directory
python examples/mail_reader_leann.py --index-dir "./my_mail_index"
# Process all emails (may take time but indexes everything)
python examples/mail_reader_leann.py --max-emails -1
# Limit number of emails processed (useful for testing)
python examples/mail_reader_leann.py --max-emails 1000
# Run a single query
python examples/mail_reader_leann.py --query "What did my boss say about deadlines?"
```
📋 Click to expand: Example queries you can try
Once the index is built, you can ask questions like:
- "Find emails from my boss about deadlines"
- "What did John say about the project timeline?"
- "Show me emails about travel expenses"
### 🔍 Time Machine for the Web: RAG Your Entire Chrome Browser History!

```bash
python examples/google_history_reader_leann.py --query "Tell me my browser history about machine learning?"
```
**38K browser entries → 6MB storage.** Your browser history becomes your personal search engine.
📋 Click to expand: Command Examples
```bash
# Use default Chrome profile (auto-finds all profiles)
python examples/google_history_reader_leann.py
# Run with custom index directory
python examples/google_history_reader_leann.py --index-dir "./my_chrome_index"
# Limit number of history entries processed (useful for testing)
python examples/google_history_reader_leann.py --max-entries 500
# Run a single query
python examples/google_history_reader_leann.py --query "What websites did I visit about machine learning?"
```
📋 Click to expand: How to find your Chrome profile
The default Chrome profile path is configured for a typical macOS setup. If you need to find your specific Chrome profile:
1. Open Terminal
2. Run: `ls ~/Library/Application\ Support/Google/Chrome/`
3. Look for folders like "Default", "Profile 1", "Profile 2", etc.
4. Use the full path as your `--chrome-profile` argument
**Common Chrome profile locations:**
- macOS: `~/Library/Application Support/Google/Chrome/Default`
- Linux: `~/.config/google-chrome/Default`
💬 Click to expand: Example queries you can try
Once the index is built, you can ask questions like:
- "What websites did I visit about machine learning?"
- "Find my search history about programming"
- "What YouTube videos did I watch recently?"
- "Show me websites I visited about travel planning"
### 💬 WeChat Detective: Unlock Your Golden Memories!

```bash
python examples/wechat_history_reader_leann.py --query "Show me all group chats about weekend plans"
```
**400K messages → 64MB storage** Search years of chat history in any language.
🔧 Click to expand: Installation Requirements
First, you need to install the WeChat exporter:
```bash
sudo packages/wechat-exporter/wechattweak-cli install
```
**Troubleshooting:**
- **Installation issues**: Check the [WeChatTweak-CLI issues page](https://github.com/sunnyyoung/WeChatTweak-CLI/issues/41)
- **Export errors**: If you encounter the error below, try restarting WeChat
```
Failed to export WeChat data. Please ensure WeChat is running and WeChatTweak is installed.
Failed to find or export WeChat data. Exiting.
```
📋 Click to expand: Command Examples
```bash
# Use default settings (recommended for first run)
python examples/wechat_history_reader_leann.py
# Run with custom export directory and wehn we run the first time, LEANN will export all chat history automatically for you
python examples/wechat_history_reader_leann.py --export-dir "./my_wechat_exports"
# Run with custom index directory
python examples/wechat_history_reader_leann.py --index-dir "./my_wechat_index"
# Limit number of chat entries processed (useful for testing)
python examples/wechat_history_reader_leann.py --max-entries 1000
# Run a single query
python examples/wechat_history_reader_leann.py --query "Show me conversations about travel plans"
```
💬 Click to expand: Example queries you can try
Once the index is built, you can ask questions like:
- "我想买魔术师约翰逊的球衣,给我一些对应聊天记录?" (Chinese: Show me chat records about buying Magic Johnson's jersey)
## 🖥️ Command Line Interface
LEANN includes a powerful CLI for document processing and search. Perfect for quick document indexing and interactive chat.
```bash
# Build an index from documents
leann build my-docs --docs ./documents
# Search your documents
leann search my-docs "machine learning concepts"
# Interactive chat with your documents
leann ask my-docs --interactive
# List all your indexes
leann list
```
**Key CLI features:**
- Auto-detects document formats (PDF, TXT, MD, DOCX)
- Smart text chunking with overlap
- Multiple LLM providers (Ollama, OpenAI, HuggingFace)
- Organized index storage in `~/.leann/indexes/`
- Support for advanced search parameters
📋 Click to expand: Complete CLI Reference
**Build Command:**
```bash
leann build INDEX_NAME --docs DIRECTORY [OPTIONS]
Options:
--backend {hnsw,diskann} Backend to use (default: hnsw)
--embedding-model MODEL Embedding model (default: facebook/contriever)
--graph-degree N Graph degree (default: 32)
--complexity N Build complexity (default: 64)
--force Force rebuild existing index
--compact Use compact storage (default: true)
--recompute Enable recomputation (default: true)
```
**Search Command:**
```bash
leann search INDEX_NAME QUERY [OPTIONS]
Options:
--top-k N Number of results (default: 5)
--complexity N Search complexity (default: 64)
--recompute-embeddings Use recomputation for highest accuracy
--pruning-strategy {global,local,proportional}
```
**Ask Command:**
```bash
leann ask INDEX_NAME [OPTIONS]
Options:
--llm {ollama,openai,hf} LLM provider (default: ollama)
--model MODEL Model name (default: qwen3:8b)
--interactive Interactive chat mode
--top-k N Retrieval count (default: 20)
```
## 🏗️ Architecture & How It Works
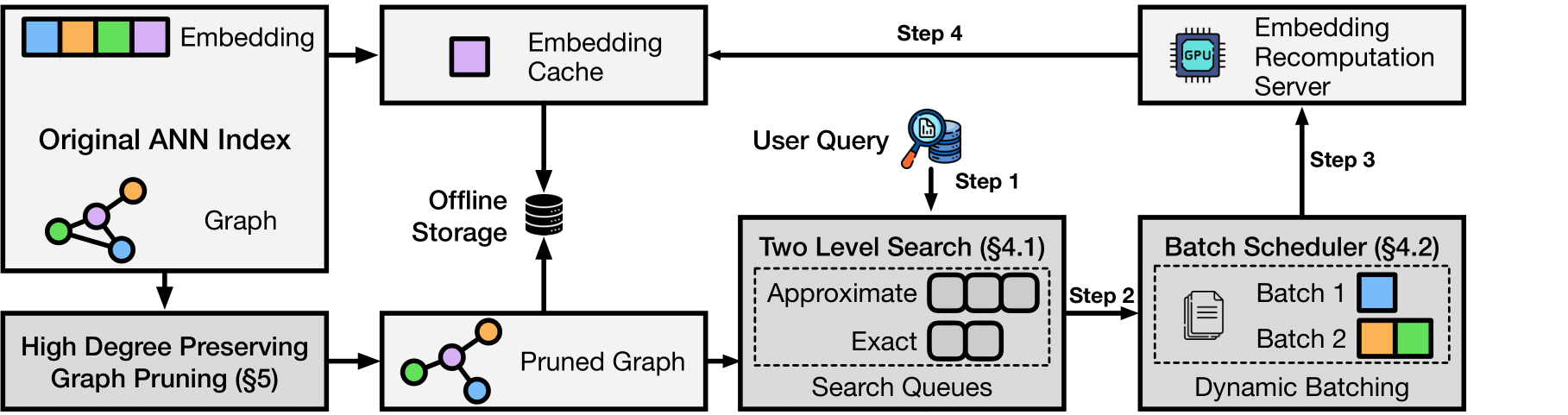
**The magic:** Most vector DBs store every single embedding (expensive). LEANN stores a pruned graph structure (cheap) and recomputes embeddings only when needed (fast).
**Core techniques:**
- **Graph-based selective recomputation:** Only compute embeddings for nodes in the search path
- **High-degree preserving pruning:** Keep important "hub" nodes while removing redundant connections
- **Dynamic batching:** Efficiently batch embedding computations for GPU utilization
- **Two-level search:** Smart graph traversal that prioritizes promising nodes
**Backends:** DiskANN or HNSW - pick what works for your data size.
## Benchmarks
📊 **[Simple Example: Compare LEANN vs FAISS →](examples/compare_faiss_vs_leann.py)**
### Storage Comparison
| System | DPR (2.1M) | Wiki (60M) | Chat (400K) | Email (780K) | Browser (38K) |
|--------|-------------|------------|-------------|--------------|---------------|
| Traditional vector database (e.g., FAISS) | 3.8 GB | 201 GB | 1.8 GB | 2.4 GB | 130 MB |
| LEANN | 324 MB | 6 GB | 64 MB | 79 MB | 6.4 MB |
| Savings| 91% | 97% | 97% | 97% | 95% |
## Reproduce Our Results
```bash
uv pip install -e ".[dev]" # Install dev dependencies
python examples/run_evaluation.py data/indices/dpr/dpr_diskann # DPR dataset
python examples/run_evaluation.py data/indices/rpj_wiki/rpj_wiki.index # Wikipedia
```
The evaluation script downloads data automatically on first run. The last three results were tested with partial personal data, and you can reproduce them with your own data!
## 🔬 Paper
If you find Leann useful, please cite:
**[LEANN: A Low-Storage Vector Index](https://arxiv.org/abs/2506.08276)**
```bibtex
@misc{wang2025leannlowstoragevectorindex,
title={LEANN: A Low-Storage Vector Index},
author={Yichuan Wang and Shu Liu and Zhifei Li and Yongji Wu and Ziming Mao and Yilong Zhao and Xiao Yan and Zhiying Xu and Yang Zhou and Ion Stoica and Sewon Min and Matei Zaharia and Joseph E. Gonzalez},
year={2025},
eprint={2506.08276},
archivePrefix={arXiv},
primaryClass={cs.DB},
url={https://arxiv.org/abs/2506.08276},
}
```
## ✨ [Detailed Features →](docs/features.md)
## 🤝 [Contributing →](docs/contributing.md)
## [FAQ →](docs/faq.md)
## 📈 [Roadmap →](docs/roadmap.md)
## 📄 License
MIT License - see [LICENSE](LICENSE) for details.
## 🙏 Acknowledgments
This work is done at [**Berkeley Sky Computing Lab**](https://sky.cs.berkeley.edu/)
---
⭐ Star us on GitHub if Leann is useful for your research or applications!
Made with ❤️ by the Leann team