



The smallest vector index in the world. RAG Everything with LEANN!
LEANN is a revolutionary vector database that makes personal AI accessible to everyone. Transform your laptop into a powerful RAG system that can index and search through millions of documents while using **97% less storage** than traditional solutions **without accuracy loss**.
RAG your **[emails](#-search-your-entire-life)**, **[browser history](#-time-machine-for-the-web)**, **[WeChat](#-wechat-detective)**, or 60M documents on your laptop, in nearly zero cost. No cloud, no API keys, completely private.
LEANN achieves this through *graph-based selective recomputation* with *high-degree preserving pruning*, computing embeddings on-demand instead of storing them all. [Read more →](#️-architecture--how-it-works)
## Why LEANN?

**The numbers speak for themselves:** Index 60 million Wikipedia articles in just 6GB instead of 201GB. Finally, your MacBook can handle enterprise-scale datasets. [See detailed benchmarks below ↓](#storage-usage-comparison)
## Why This Matters
🔒 **Privacy:** Your data never leaves your laptop. No OpenAI, no cloud, no "terms of service".
🪶 **Lightweight:** Minimal resource requirements - runs smoothly on any laptop without specialized hardware.
📈 **Scalability:** Organize our messy personal data that would crash traditional vector DBs, with performance that gets better as your data grows more personalized.
✨ **No Accuracy Loss:** Maintain the same search quality as heavyweight solutions while using 97% less storage.
## Quick Start in 1 minute
```bash
git clone git@github.com:yichuan520030910320/LEANN-RAG.git leann
cd leann
git submodule update --init --recursive
```
**macOS:**
```bash
brew install llvm libomp boost protobuf
export CC=$(brew --prefix llvm)/bin/clang
export CXX=$(brew --prefix llvm)/bin/clang++
uv sync
```
**Linux (Ubuntu/Debian):**
```bash
sudo apt-get install libomp-dev libboost-all-dev protobuf-compiler libabsl-dev libmkl-full-dev libaio-dev
uv sync
```
**Ollama Setup (Optional for Local LLM):**
*We support both hf-transformers and Ollama for local LLMs. Ollama is recommended for faster performance.*
*macOS:*
```bash
# Install Ollama
brew install ollama
# Pull a lightweight model (recommended for consumer hardware)
ollama pull llama3.2:1b
```
*Linux:*
```bash
# Install Ollama
curl -fsSL https://ollama.ai/install.sh | sh
# Start Ollama service manually
ollama serve &
# Pull a lightweight model (recommended for consumer hardware)
ollama pull llama3.2:1b
```
You can also replace `llama3.2:1b` to `deepseek-r1:1.5b` or `qwen3:4b` for better performance but higher memory usage.
## Dead Simple API
Just 3 lines of code. Our declarative API makes RAG as easy as writing a config file:
```python
from leann.api import LeannBuilder, LeannSearcher
# Index your entire email history (90K emails = 14MB vs 305MB)
builder = LeannBuilder(backend_name="hnsw")
builder.add_from_mailbox("~/Library/Mail") # Your actual emails
builder.build_index("my_life.leann")
# Ask questions about your own data
searcher = LeannSearcher("my_life.leann")
searcher.search("What did my boss say about the deadline?")
searcher.search("Find emails about vacation requests")
searcher.search("Show me all conversations with John about the project")
```
**That's it.** No cloud setup, no API keys, no "fine-tuning". Just your data, your questions, your laptop.
[Try the interactive demo →](demo.ipynb)
## Wild Things You Can Do
LEANN supports RAGing a lot of data sources, like .pdf, .txt, .docx, .md, and also supports RAGing your WeChat, Google Search History, and more.
### 🕵️ Search Your Entire Life
```bash
python examples/mail_reader_leann.py
# "What did my boss say about the Christmas party last year?"
# "Find all emails from my mom about birthday plans"
```
**90K emails → 14MB.** Finally, search your email like you search Google.
📋 Click to expand: Command Examples
```bash
# Use default mail path (works for most macOS setups)
python examples/mail_reader_leann.py
# Run with custom index directory
python examples/mail_reader_leann.py --index-dir "./my_mail_index"
# Process all emails (may take time but indexes everything)
python examples/mail_reader_leann.py --max-emails -1
# Limit number of emails processed (useful for testing)
python examples/mail_reader_leann.py --max-emails 1000
# Run a single query
python examples/mail_reader_leann.py --query "What did my boss say about deadlines?"
```
### 🌐 Time Machine for the Web
```bash
python examples/google_history_reader_leann.py
# "What was that AI paper I read last month?"
# "Show me all the cooking videos I watched"
```
**38K browser entries → 6MB.** Your browser history becomes your personal search engine.
📋 Click to expand: Command Examples
```bash
# Use default Chrome profile (auto-finds all profiles)
python examples/google_history_reader_leann.py
# Run with custom index directory
python examples/google_history_reader_leann.py --index-dir "./my_chrome_index"
# Limit number of history entries processed (useful for testing)
python examples/google_history_reader_leann.py --max-entries 500
# Run a single query
python examples/google_history_reader_leann.py --query "What websites did I visit about machine learning?"
```
### 💬 WeChat Detective
```bash
python examples/wechat_history_reader_leann.py
# "我想买魔术师约翰逊的球衣,给我一些对应聊天记录"
# "Show me all group chats about weekend plans"
```
**400K messages → 64MB.** Search years of chat history in any language.
📋 Click to expand: Command Examples
```bash
# Use default settings (recommended for first run)
python examples/wechat_history_reader_leann.py
# Run with custom export directory
python examples/wechat_history_reader_leann.py --export-dir "./my_wechat_exports"
# Run with custom index directory
python examples/wechat_history_reader_leann.py --index-dir "./my_wechat_index"
# Limit number of chat entries processed (useful for testing)
python examples/wechat_history_reader_leann.py --max-entries 1000
# Run a single query
python examples/wechat_history_reader_leann.py --query "Show me conversations about travel plans"
```
### 📚 Personal Wikipedia
```bash
# Index 60M Wikipedia articles in 6GB (not 201GB)
python examples/build_massive_index.py --source wikipedia
# "Explain quantum computing like I'm 5"
# "What are the connections between philosophy and AI?"
```
**PDF RAG Demo (using LlamaIndex for document parsing and Leann for indexing/search)**
This demo showcases how to build a RAG system for PDF/md documents using Leann.
1. Place your PDF files (and other supported formats like .docx, .pptx, .xlsx) into the `examples/data/` directory.
2. Ensure you have an `OPENAI_API_KEY` set in your environment variables or in a `.env` file for the LLM to function.
## 🏗️ Architecture & How It Works
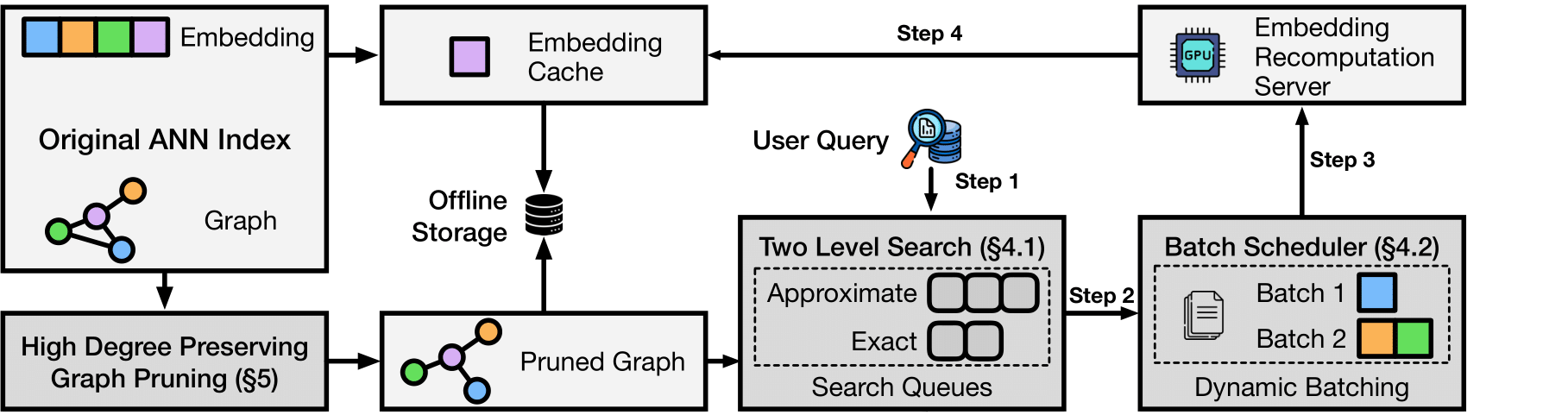
**The magic:** Most vector DBs store every single embedding (expensive). LEANN stores a pruned graph structure (cheap) and recomputes embeddings only when needed (fast).
**Core techniques:**
- **Graph-based selective recomputation:** Only compute embeddings for nodes in the search path
- **High-degree preserving pruning:** Keep important "hub" nodes while removing redundant connections
- **Dynamic batching:** Efficiently batch embedding computations for GPU utilization
- **Two-level search:** Smart graph traversal that prioritizes promising nodes
**Backends:** DiskANN or HNSW - pick what works for your data size.
## Benchmarks
Run the comparison yourself:
```bash
python examples/compare_faiss_vs_leann.py
```
| System | Storage |
|--------|---------|
| FAISS HNSW | 5.5 MB |
| LEANN | 0.5 MB |
| **Savings** | **91%** |
Same dataset, same hardware, same embedding model. LEANN just works better.
## Reproduce Our Results
```bash
uv pip install -e ".[dev]" # Install dev dependencies
python examples/run_evaluation.py data/indices/dpr/dpr_diskann # DPR dataset
python examples/run_evaluation.py data/indices/rpj_wiki/rpj_wiki.index # Wikipedia
```
The evaluation script downloads data automatically on first run.
### Storage Usage Comparison
| System | DPR (2.1M chunks) | RPJ-wiki (60M chunks) | Chat history (400K messages) | Apple emails (90K messages chunks) |Google Search History (38K entries)
|-----------------------|------------------|------------------------|-----------------------------|------------------------------|------------------------------|
| Traditional Vector DB(FAISS) | 3.8 GB | 201 GB | 1.8G | 305.8 MB |130.4 MB |
| **LEANN** | **324 MB** | **6 GB** | **64 MB** | **14.8 MB** |**6.4MB** |
| **Reduction** | **91% smaller** | **97% smaller** | **97% smaller** | **95% smaller** |**95% smaller** |
*Benchmarks run on Apple M3 Pro 36 GB*
## 🔬 Paper
If you find Leann useful, please cite:
**[LEANN: A Low-Storage Vector Index](https://arxiv.org/abs/2506.08276)**
```bibtex
@misc{wang2025leannlowstoragevectorindex,
title={LEANN: A Low-Storage Vector Index},
author={Yichuan Wang and Shu Liu and Zhifei Li and Yongji Wu and Ziming Mao and Yilong Zhao and Xiao Yan and Zhiying Xu and Yang Zhou and Ion Stoica and Sewon Min and Matei Zaharia and Joseph E. Gonzalez},
year={2025},
eprint={2506.08276},
archivePrefix={arXiv},
primaryClass={cs.DB},
url={https://arxiv.org/abs/2506.08276},
}
```
## 🤝 Contributing
We welcome contributions! Leann is built by the community, for the community.
### Ways to Contribute
- 🐛 **Bug Reports**: Found an issue? Let us know!
- 💡 **Feature Requests**: Have an idea? We'd love to hear it!
- 🔧 **Code Contributions**: PRs welcome for all skill levels
- 📖 **Documentation**: Help make Leann more accessible
- 🧪 **Benchmarks**: Share your performance results
## 📈 Roadmap
### 🎯 Q2 2025
- [X] DiskANN backend with MIPS/L2/Cosine support
- [X] HNSW backend integration
- [X] Real-time embedding pipeline
- [X] Memory-efficient graph pruning
### 🚀 Q3 2025
- [ ] Advanced caching strategies
- [ ] Add contextual-retrieval https://www.anthropic.com/news/contextual-retrieval
- [ ] Add sleep-time-compute and summarize agent! to summarilze the file on computer!
- [ ] Add OpenAI recompute API
### 🌟 Q4 2025
- [ ] Integration with LangChain/LlamaIndex
- [ ] Visual similarity search
- [ ] Query rewrtiting, rerank and expansion
## 📄 License
MIT License - see [LICENSE](LICENSE) for details.
## 🙏 Acknowledgments
- **Microsoft Research** for the DiskANN algorithm
- **Meta AI** for FAISS and optimization insights
- **HuggingFace** for the transformer ecosystem
- **Our amazing contributors** who make this possible
---
⭐ Star us on GitHub if Leann is useful for your research or applications!
Made with ❤️ by the Leann team