🚀 LEANN: A Low-Storage Vector Index




⚡ Storage Saving RAG sytem on Consumer Device
Quick Start •
Features •
Benchmarks •
Paper
---
## 🌟 What is Leann?
**Leann** revolutionizes Retrieval-Augmented Generation (RAG) by eliminating the storage bottleneck of traditional vector databases. Instead of pre-computing and storing billions of embeddings, Leann dynamically computes embeddings at query time using optimized graph-based search algorithms.
### 🎯 Why Leann?
Traditional RAG systems face a fundamental trade-off:
- **💾 Storage**: Storing embeddings for millions of documents requires massive disk space
- **🔄 Memory overhead**: The indexes LlamaIndex uses usually face high memory overhead (e.g., in-memory vector databases)
- **💰 Cost**: Vector databases are expensive to scale
**Leann revolutionizes this with Graph-based recomputation and cutting-edge system optimizations:**
- ✅ **Zero embedding storage** - Only graph structure is persisted, reducing storage by 94-97%
- ✅ **Real-time computation** - Embeddings computed on-demand with low latency
- ✅ **Memory efficient** - Runs on consumer hardware with theoretical zero memory overhead
- ✅ **Graph-based optimization** - Advanced pruning techniques for efficient search while keeping low storage cost, with batching and overlapping strategies using low-precision search to optimize latency
- ✅ **Pluggable backends** - Support for DiskANN, HNSW, and other ANN algorithms (welcome contributions!)
## 🚀 Quick Start
### Installation
```bash
git clone git@github.com:yichuan520030910320/LEANN-RAG.git leann
cd leann
git submodule update --init --recursive
```
**macOS:**
```bash
brew install llvm libomp boost protobuf
export CC=$(brew --prefix llvm)/bin/clang
export CXX=$(brew --prefix llvm)/bin/clang++
uv sync
```
**Linux (Ubuntu/Debian):**
```bash
sudo apt-get install libomp-dev libboost-all-dev protobuf-compiler libabsl-dev libmkl-full-dev libaio-dev
uv sync
```
### 🚀 30-Second Example
Try it out in [**demo.ipynb**](demo.ipynb)
```python
from leann.api import LeannBuilder, LeannSearcher
# 1. Build index (no embeddings stored!)
builder = LeannBuilder(backend_name="hnsw")
builder.add_text("C# is a powerful programming language")
builder.add_text("Python is a powerful programming language")
builder.add_text("Machine learning transforms industries")
builder.add_text("Neural networks process complex data")
builder.add_text("Leann is a great storage saving engine for RAG on your macbook")
builder.build_index("knowledge.leann")
# 2. Search with real-time embeddings
searcher = LeannSearcher("knowledge.leann")
results = searcher.search("C++ programming languages", top_k=2, recompute_beighbor_embeddings=True)
print(results)
```
### Run the Demo (support .pdf,.txt,.docx, .pptx, .csv, .md etc)
```bash
uv run ./examples/main_cli_example.py
```
or you want to use python
```bash
source .venv/bin/activate
python ./examples/main_cli_example.py
```
**PDF RAG Demo (using LlamaIndex for document parsing and Leann for indexing/search)**
This demo showcases how to build a RAG system for PDF/md documents using Leann.
1. Place your PDF files (and other supported formats like .docx, .pptx, .xlsx) into the `examples/data/` directory.
2. Ensure you have an `OPENAI_API_KEY` set in your environment variables or in a `.env` file for the LLM to function.
## ✨ Features
### 🔥 Core Features
- **🔄 Real-time Embeddings** - Eliminate heavy embedding storage with dynamic computation using optimized ZMQ servers and highly optimized search paradigm (overlapping and batching) with highly optimized embedding engine
- **📈 Scalable Architecture** - Handles millions of documents on consumer hardware; the larger your dataset, the more LEANN can save
- **🎯 Graph Pruning** - Advanced techniques to minimize the storage overhead of vector search to a limited footprint
- **🏗️ Pluggable Backends** - DiskANN, HNSW/FAISS with unified API
### 🛠️ Technical Highlights
- **🔄 Recompute Mode** - Highest accuracy scenarios while eliminating vector storage overhead
- **⚡ Zero-copy Operations** - Minimize IPC overhead by transferring distances instead of embeddings
- **🚀 High-throughput Embedding Pipeline** - Optimized batched processing for maximum efficiency
- **🎯 Two-level Search** - Novel coarse-to-fine search overlap for accelerated query processing (optional)
- **💾 Memory-mapped Indices** - Fast startup with raw text mapping to reduce memory overhead
- **🚀 MLX Support** - Ultra-fast recompute with quantized embedding models, accelerating building and search by 10-100x ([minimal example](test/build_mlx_index.py))
### 🎨 Developer Experience
- **Simple Python API** - Get started in minutes
- **Extensible backend system** - Easy to add new algorithms
- **Comprehensive examples** - From basic usage to production deployment
## Applications on your MacBook
### 📧 Lightweight RAG on your Apple Mail
LEANN can create a searchable index of your Apple Mail emails, allowing you to query your email history using natural language.
#### Quick Start
📋 Click to expand: Command Examples
```bash
# Use default mail path (works for most macOS setups)
python examples/mail_reader_leann.py
# Specify your own mail path
python examples/mail_reader_leann.py --mail-path "/Users/yourname/Library/Mail/V10/..."
# Run with custom index directory
python examples/mail_reader_leann.py --index-dir "./my_mail_index"
# Limit number of emails processed (useful for testing)
python examples/mail_reader_leann.py --max-emails 1000
# Run a single query
python examples/mail_reader_leann.py --query "Find emails about project deadlines"
```
#### Finding Your Mail Path
🔍 Click to expand: How to find your mail path
The default mail path is configured for a typical macOS setup. If you need to find your specific mail path:
1. Open Terminal
2. Run: `find ~/Library/Mail -name "Messages" -type d | head -5`
3. Use the parent directory(ended with Data) of the Messages folder as your `--mail-path`
#### Example Queries
💬 Click to expand: Example queries you can try
Once the index is built, you can ask questions like:
- "Show me emails about meeting schedules"
- "Find emails from my boss about deadlines"
- "What did John say about the project timeline?"
- "Show me emails about travel expenses"
### 🌐 Lightweight RAG on your Google Chrome History
LEANN can create a searchable index of your Chrome browser history, allowing you to query your browsing history using natural language.
#### Quick Start
📋 Click to expand: Command Examples
Note you need to quit google right now to successfully run this.
```bash
# Use default Chrome profile (auto-finds all profiles) and recommand method to run this because usually default file is enough
python examples/google_history_reader_leann.py
# Run with custom index directory
python examples/google_history_reader_leann.py --index-dir "./my_chrome_index"
# Limit number of history entries processed (useful for testing)
python examples/google_history_reader_leann.py --max-entries 500
# Run a single query
python examples/google_history_reader_leann.py --query "What websites did I visit about machine learning?"
# Use only a specific profile (disable auto-find)
python examples/google_history_reader_leann.py --chrome-profile "~/Library/Application Support/Google/Chrome/Default" --no-auto-find-profiles
```
#### Finding Your Chrome Profile
🔍 Click to expand: How to find your Chrome profile
The default Chrome profile path is configured for a typical macOS setup. If you need to find your specific Chrome profile:
1. Open Terminal
2. Run: `ls ~/Library/Application\ Support/Google/Chrome/`
3. Look for folders like "Default", "Profile 1", "Profile 2", etc.
4. Use the full path as your `--chrome-profile` argument
**Common Chrome profile locations:**
- macOS: `~/Library/Application Support/Google/Chrome/Default`
- Linux: `~/.config/google-chrome/Default`
#### Example Queries
💬 Click to expand: Example queries you can try
Once the index is built, you can ask questions like:
- "What websites did I visit about machine learning?"
- "Find my search history about programming"
- "What YouTube videos did I watch recently?"
- "Show me websites I visited about travel planning"
### 💬 Lightweight RAG on your WeChat History
LEANN can create a searchable index of your WeChat chat history, allowing you to query your conversations using natural language.
#### Prerequisites
🔧 Click to expand: Installation Requirements
First, you need to install the WeChat exporter:
```bash
sudo packages/wechat-exporter/wechattweak-cli install
```
**Troubleshooting**: If you encounter installation issues, check the [WeChatTweak-CLI issues page](https://github.com/sunnyyoung/WeChatTweak-CLI/issues/41).
#### Quick Start
📋 Click to expand: Command Examples
```bash
# Use default settings (recommended for first run)
python examples/wechat_history_reader_leann.py
# Run with custom export directory and wehn we run the first time, LEANN will export all chat history automatically for you
python examples/wechat_history_reader_leann.py --export-dir "./my_wechat_exports"
# Run with custom index directory
python examples/wechat_history_reader_leann.py --index-dir "./my_wechat_index"
# Limit number of chat entries processed (useful for testing)
python examples/wechat_history_reader_leann.py --max-entries 1000
# Run a single query
python examples/wechat_history_reader_leann.py --query "Show me conversations about travel plans"
```
#### Example Queries
💬 Click to expand: Example queries you can try
Once the index is built, you can ask questions like:
- "我想买魔术师约翰逊的球衣,给我一些对应聊天记录?" (Chinese: Show me chat records about buying Magic Johnson's jersey)
## ⚡ Performance Comparison
### LEANN vs Faiss HNSW
We benchmarked LEANN against the popular Faiss HNSW implementation to demonstrate the significant memory and storage savings our approach provides:
```bash
# Run the comparison benchmark
python examples/compare_faiss_vs_leann.py
```
#### 🎯 Results Summary
| Metric | Faiss HNSW | LEANN HNSW | **Improvement** |
|--------|------------|-------------|-----------------|
| **Storage Size** | 5.5 MB | 0.5 MB | **11.4x smaller** (5.0 MB saved) |
#### 📈 Key Takeaways
- **💾 Storage Optimization**: LEANN requires **91% less storage** for the same dataset
- **⚖️ Fair Comparison**: Both systems tested on identical hardware with the same 2,573 document dataset and the same embedding model and chunk method
> **Note**: Results may vary based on dataset size, hardware configuration, and query patterns. The comparison excludes text storage to focus purely on index structures.
*Benchmark results obtained on Apple Silicon with consistent environmental conditions*
## 📊 Benchmarks
### How to Reproduce Evaluation Results
Reproducing our benchmarks is straightforward. The evaluation script is designed to be self-contained, automatically downloading all necessary data on its first run.
#### 1. Environment Setup
First, ensure you have followed the installation instructions in the [Quick Start](#-quick-start) section. This will install all core dependencies.
Next, install the optional development dependencies, which include the `huggingface-hub` library required for automatic data download:
```bash
# This command installs all development dependencies
uv pip install -e ".[dev]"
```
#### 2. Run the Evaluation
Simply run the evaluation script. The first time you run it, it will detect that the data is missing, download it from Hugging Face Hub, and then proceed with the evaluation.
**To evaluate the DPR dataset:**
```bash
python examples/run_evaluation.py data/indices/dpr/dpr_diskann
```
**To evaluate the RPJ-Wiki dataset:**
```bash
python examples/run_evaluation.py data/indices/rpj_wiki/rpj_wiki.index
```
The script will print the recall and search time for each query, followed by the average results.
### Storage Usage Comparison
| System | DPR(2.1M docs) | RPJ-wiki(60M docs) | Chat history(5K messages) |
| --------------------- | ---------------- | ---------------- | ---------------- |
| Traditional Vector DB | 3.8 GB | 201 GB | 22.8 MB |
| **LEANN** | **324 MB** | **6 GB** | **0.78 MB** |
| **Reduction** | **91% smaller** | **97% smaller** | **97% smaller** |
*Benchmarks run on Apple M3 Pro 36 GB*
## 🏗️ Architecture
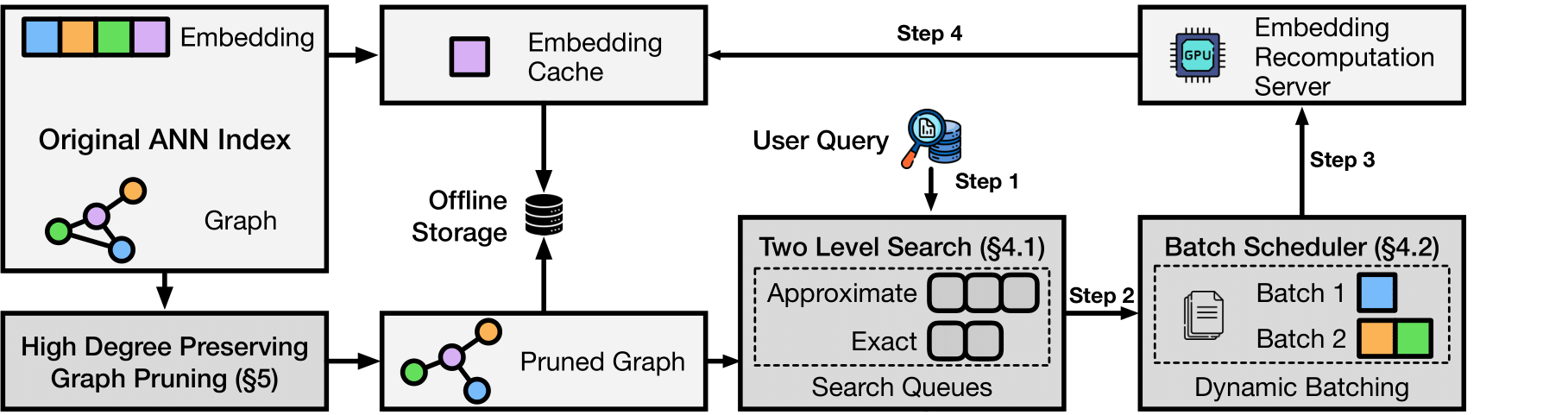
## 🔬 Paper
If you find Leann useful, please cite:
**[LEANN: A Low-Storage Vector Index](https://arxiv.org/abs/2506.08276)**
```bibtex
@misc{wang2025leannlowstoragevectorindex,
title={LEANN: A Low-Storage Vector Index},
author={Yichuan Wang and Shu Liu and Zhifei Li and Yongji Wu and Ziming Mao and Yilong Zhao and Xiao Yan and Zhiying Xu and Yang Zhou and Ion Stoica and Sewon Min and Matei Zaharia and Joseph E. Gonzalez},
year={2025},
eprint={2506.08276},
archivePrefix={arXiv},
primaryClass={cs.DB},
url={https://arxiv.org/abs/2506.08276},
}
```
## 🤝 Contributing
We welcome contributions! Leann is built by the community, for the community.
### Ways to Contribute
- 🐛 **Bug Reports**: Found an issue? Let us know!
- 💡 **Feature Requests**: Have an idea? We'd love to hear it!
- 🔧 **Code Contributions**: PRs welcome for all skill levels
- 📖 **Documentation**: Help make Leann more accessible
- 🧪 **Benchmarks**: Share your performance results
## 📈 Roadmap
### 🎯 Q2 2025
- [X] DiskANN backend with MIPS/L2/Cosine support
- [X] HNSW backend integration
- [X] Real-time embedding pipeline
- [X] Memory-efficient graph pruning
### 🚀 Q3 2025
- [ ] Advanced caching strategies
- [ ] Add contextual-retrieval https://www.anthropic.com/news/contextual-retrieval
- [ ] Add sleep-time-compute and summarize agent! to summarilze the file on computer!
- [ ] Add OpenAI recompute API
### 🌟 Q4 2025
- [ ] Integration with LangChain/LlamaIndex
- [ ] Visual similarity search
- [ ] Query rewrtiting, rerank and expansion
## 📄 License
MIT License - see [LICENSE](LICENSE) for details.
## 🙏 Acknowledgments
- **Microsoft Research** for the DiskANN algorithm
- **Meta AI** for FAISS and optimization insights
- **HuggingFace** for the transformer ecosystem
- **Our amazing contributors** who make this possible
---
⭐ Star us on GitHub if Leann is useful for your research or applications!
Made with ❤️ by the Leann team