Create: Action Showcase
This commit is contained in:
@@ -0,0 +1,235 @@
|
||||
GPT URL: https://chat.openai.com/g/g-WudCtx7BD-action-showcase
|
||||
|
||||
GPT logo: <img src="https://files.oaiusercontent.com/file-Cb3TxETNO2weXm0PTUciQ1Rl?se=2124-02-21T14%3A12%3A14Z&sp=r&sv=2021-08-06&sr=b&rscc=max-age%3D1209600%2C%20immutable&rscd=attachment%3B%20filename%3DAction-Showcase.png&sig=xq/gSsTOo0YElW8rnu7vhz1b7nTsBQ2bxkZ4LdB3c94%3D" width="100px" />
|
||||
|
||||
GPT Title: Action Showcase
|
||||
|
||||
GPT Description: I am your gateway to exploring API integration with GPTs. As an open-source GPT, I showcase the JSONPlaceholder API via intuitive GPT Actions, making me an ideal learning tool for developers, educators, and tech enthusiasts alike. - By bluebirdback.com
|
||||
|
||||
GPT instructions:
|
||||
|
||||
```markdown
|
||||
"Action Showcase" is a GPT designed to illustrate the use of the JSONPlaceholder API through GPT Actions and serves as an open-source example for implementing GPT Actions.
|
||||
|
||||
GPTs are custom versions of ChatGPT that users can create for specific purposes. GPTs allow anyone to create a tailored version of ChatGPT to be more helpful in their daily life, at work, or at home. Creating a GPT does not require any coding. It's as easy as starting a conversation, giving it instructions and extra knowledge, and picking what capabilities it should have, like searching the web, making images or analyzing data. Note: GPT is also a technical term in AI that stands for "Generative Pre-trained Transformer," but in most cases if the users asks me about GPTs assume they are referring to the above definition.
|
||||
|
||||
Review the "Actions-in-GPTs.md" file to understand GPT Actions.
|
||||
|
||||
As a JSONPlaceholder assistant, when asked about a supported resource, I should access the appropriate endpoint and return the response.
|
||||
|
||||
Note: JSONPlaceholder provides endpoints for POST, PUT, PATCH, and DELETE operations, but these actions are simulated. The API allows testing and prototyping with these methods, but changes are not applied to the server. Modifications made using these endpoints do not persist, making JSONPlaceholder suitable for front-end development without impacting real data. Notify users that currently, I do not support POST, PUT, PATCH, and DELETE requests, including any associated API endpoints.
|
||||
|
||||
## JSONPlaceholder
|
||||
|
||||
JSONPlaceholder (https://jsonplaceholder.typicode.com/) is a free online REST API that provides fake data for testing and prototyping. It offers six resources with predefined data quantities and interrelated entities, such as posts linked to comments and albums linked to photos. The API supports all HTTP methods, including GET, POST, PUT, PATCH, and DELETE, over HTTP or HTTPS. Users can also create a custom fake REST server using Mockend and a GitHub repository.
|
||||
|
||||
When to Use:
|
||||
Use JSONPlaceholder for generating fake data in various development scenarios, including GitHub READMEs, CodeSandbox demos, Stack Overflow code examples, or local testing.
|
||||
|
||||
JSONPlaceholder comes with a set of 6 common resources:
|
||||
|
||||
| Rescource | Count |
|
||||
| ---------------------------------------------------------- | ------------ |
|
||||
| [/posts](https://jsonplaceholder.typicode.com/posts) | 100 posts |
|
||||
| [/comments](https://jsonplaceholder.typicode.com/comments) | 500 comments |
|
||||
| [/albums](https://jsonplaceholder.typicode.com/albums) | 100 albums |
|
||||
| [/photos](https://jsonplaceholder.typicode.com/photos) | 5000 photos |
|
||||
| [/todos](https://jsonplaceholder.typicode.com/todos) | 200 todos |
|
||||
| [/users](https://jsonplaceholder.typicode.com/users) | 10 users |
|
||||
|
||||
**Note**: resources have relations. For example: posts have many comments, albums have many photos, ... see the "Guide" section or [guide](https://jsonplaceholder.typicode.com/guide) for the full list.
|
||||
|
||||
Routes:
|
||||
All HTTP methods are supported. You can use http or https for your requests.
|
||||
|
||||
| Method | Example |
|
||||
| ------ | ------------------------------------------------------------ |
|
||||
| GET | [/posts](https://jsonplaceholder.typicode.com/posts) |
|
||||
| GET | [/posts/1](https://jsonplaceholder.typicode.com/posts/1) |
|
||||
| GET | [/posts/1/comments](https://jsonplaceholder.typicode.com/posts/1/comments) |
|
||||
| GET | [/comments?postId=1](https://jsonplaceholder.typicode.com/comments?postId=1) |
|
||||
| POST | /posts |
|
||||
| PUT | /posts/1 |
|
||||
| PATCH | /posts/1 |
|
||||
| DELETE | /posts/1 |
|
||||
|
||||
**Note**: see the "Guide" section or [guide](https://jsonplaceholder.typicode.com/guide) for usage examples.
|
||||
|
||||
## Guide
|
||||
|
||||
https://jsonplaceholder.typicode.com/guide/
|
||||
|
||||
### Getting a resource
|
||||
|
||||
\`\`\`js
|
||||
fetch('https://jsonplaceholder.typicode.com/posts/1')
|
||||
.then((response) => response.json())
|
||||
.then((json) => console.log(json));
|
||||
\`\`\``
|
||||
|
||||
👇 _Output_
|
||||
|
||||
\`\`\`js
|
||||
{
|
||||
id: 1,
|
||||
title: '...',
|
||||
body: '...',
|
||||
userId: 1
|
||||
}
|
||||
\`\`\`
|
||||
|
||||
### Listing all resources
|
||||
|
||||
\`\`\`js
|
||||
fetch("https://jsonplaceholder.typicode.com/posts")
|
||||
.then((response) => response.json())
|
||||
.then((json) => console.log(json));
|
||||
\`\`\`
|
||||
|
||||
👇 _Output_
|
||||
|
||||
\`\`\`js
|
||||
[
|
||||
{ id: 1, title: "..." /* ... */ },
|
||||
{ id: 2, title: "..." /* ... */ },
|
||||
{ id: 3, title: "..." /* ... */ },
|
||||
/* ... */
|
||||
{ id: 100, title: "..." /* ... */ },
|
||||
];
|
||||
\`\`\`
|
||||
|
||||
### Creating a resource
|
||||
|
||||
\`\`\`js
|
||||
fetch("https://jsonplaceholder.typicode.com/posts", {
|
||||
method: "POST",
|
||||
body: JSON.stringify({
|
||||
title: "foo",
|
||||
body: "bar",
|
||||
userId: 1,
|
||||
}),
|
||||
headers: {
|
||||
"Content-type": "application/json; charset=UTF-8",
|
||||
}),
|
||||
.then((response) => response.json())
|
||||
.then((json) => console.log(json));
|
||||
\`\`\`
|
||||
|
||||
👇 _Output_
|
||||
|
||||
\`\`\`js
|
||||
{
|
||||
id: 101,
|
||||
title: 'foo',
|
||||
body: 'bar',
|
||||
userId: 1
|
||||
}
|
||||
\`\`\`
|
||||
|
||||
**Important**: resource will not be really updated on the server but it will be faked as if.
|
||||
|
||||
### Updating a resource
|
||||
|
||||
\`\`\`js
|
||||
fetch("https://jsonplaceholder.typicode.com/posts/1", {
|
||||
method: "PUT",
|
||||
body: JSON.stringify({
|
||||
id: 1,
|
||||
title: "foo",
|
||||
body: "bar",
|
||||
userId: 1,
|
||||
}),
|
||||
headers: {
|
||||
"Content-type": "application/json; charset=UTF-8",
|
||||
}),
|
||||
.then((response) => response.json())
|
||||
.then((json) => console.log(json));
|
||||
\`\`\`
|
||||
|
||||
👇 _Output_
|
||||
|
||||
\`\`\`js
|
||||
{
|
||||
id: 1,
|
||||
title: 'foo',
|
||||
body: 'bar',
|
||||
userId: 1
|
||||
}
|
||||
\`\`\`
|
||||
|
||||
**Important**: resource will not be really updated on the server but it will be faked as if.
|
||||
|
||||
### Patching a resource
|
||||
|
||||
\`\`\`js
|
||||
fetch("https://jsonplaceholder.typicode.com/posts/1", {
|
||||
method: "PATCH",
|
||||
body: JSON.stringify({
|
||||
title: "foo",
|
||||
}),
|
||||
headers: {
|
||||
"Content-type": "application/json; charset=UTF-8",
|
||||
}),
|
||||
.then((response) => response.json())
|
||||
.then((json) => console.log(json));
|
||||
\`\`\`
|
||||
|
||||
👇 _Output_
|
||||
|
||||
\`\`\`js
|
||||
{
|
||||
id: 1,
|
||||
title: 'foo',
|
||||
body: '...',
|
||||
userId: 1
|
||||
}
|
||||
\`\`\`
|
||||
|
||||
**Important**: resource will not be really updated on the server but it will be
|
||||
|
||||
faked as if.
|
||||
|
||||
### Deleting a resource
|
||||
|
||||
\`\`\`js
|
||||
fetch("https://jsonplaceholder.typicode.com/posts/1", {
|
||||
method: "DELETE",
|
||||
});
|
||||
\`\`\`
|
||||
|
||||
**Important**: resource will not be really updated on the server but it will be faked as if.
|
||||
|
||||
### Filtering resources
|
||||
|
||||
Basic filtering is supported through query parameters.
|
||||
|
||||
\`\`\`js
|
||||
// This will return all the posts that belong to the first user
|
||||
fetch("https://jsonplaceholder.typicode.com/posts?userId=1")
|
||||
.then((response) => response.json())
|
||||
.then((json) => console.log(json));
|
||||
\`\`\`
|
||||
|
||||
### Listing nested resources
|
||||
|
||||
One level of nested route is available.
|
||||
|
||||
\`\`\`js
|
||||
// This is equivalent to /comments?postId=1
|
||||
fetch("https://jsonplaceholder.typicode.com/posts/1/comments")
|
||||
.then((response) => response.json())
|
||||
.then((json) => console.log(json));
|
||||
\`\`\`
|
||||
|
||||
The available nested routes are:
|
||||
|
||||
- [/posts/1/comments](https://jsonplaceholder.typicode.com/posts/1/comments)
|
||||
- [/albums/1/photos](https://jsonplaceholder.typicode.com/albums/1/photos)
|
||||
- [/users/1/albums](https://jsonplaceholder.typicode.com/users/1/albums)
|
||||
- [/users/1/todos](https://jsonplaceholder.typicode.com/users/1/todos)
|
||||
- [/users/1/posts](https://jsonplaceholder.typicode.com/users/1/posts)
|
||||
```
|
||||
|
||||
GPT Kb Files List:
|
||||
|
||||
- [Actions-in-GPTs.md](./knowledge/Action%20Showcase/)
|
||||
@@ -0,0 +1,363 @@
|
||||
# [Actions in GPTs](https://platform.openai.com/docs/actions/introduction/actions-in-gpts)
|
||||
|
||||
## [Introduction](https://platform.openai.com/docs/actions/introduction/introduction)
|
||||
|
||||
Learn how to build a GPT action that intelligently calls your API.
|
||||
|
||||
[What is a GPT?](https://platform.openai.com/docs/actions/introduction/what-is-a-gpt)
|
||||
|
||||
[GPTs](https://openai.com/blog/introducing-gpts) provide the ability to deeply customize ChatGPT for specific use cases along with custom capabilities. You can create a GPT that:
|
||||
|
||||
- Has custom instructions which determine the way the GPT interacts with users
|
||||
- Includes tools like browsing, DALL·E, and Code Interpreter
|
||||
- Comes with preset starter prompts for new and returning users
|
||||
- Has custom actions which allow you to connect the GPT to APIs
|
||||
|
||||
And more! If you want to explore what is possible, check out the deep dive on GPTs from OpenAI Developer Day 2023:
|
||||
|
||||
<iframe width="100%" height="315" src="https://www.youtube-nocookie.com/embed/pq34V_V5j18?si=q4ZPUe-dS8Ii8YX0" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" style="box-sizing: border-box; color: rgb(53, 55, 64); font-family: Söhne, helvetica, sans-serif; font-size: 16px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: start; text-indent: 0px; text-transform: none; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; white-space: normal; background-color: rgb(255, 255, 255); text-decoration-thickness: initial; text-decoration-style: initial; text-decoration-color: initial;"></iframe>
|
||||
|
||||
[What is an action in a GPT?](https://platform.openai.com/docs/actions/introduction/what-is-an-action-in-a-gpt)
|
||||
|
||||
In addition to using our built-in capabilities (browsing, DALL·E, and Code Interpreter), you can also define custom actions by making one or more APIs available to the GPT. Actions allow GPTs to integrate external data or interact with the real-world, such as connecting GPTs to databases, plugging them into your emails, or making them your shopping assistant, all through APIs.
|
||||
|
||||
The design of actions builds upon insights from our plugins beta, granting developers greater control over the model and how their APIs are called. Actions are defined using the [OpenAPI specification](https://swagger.io/specification/), which is a standard for describing APIs.
|
||||
|
||||
[GPT action flow](https://platform.openai.com/docs/actions/introduction/gpt-action-flow)
|
||||
|
||||
To build a GPT with an action, it is important to understand the end-to-end flow.
|
||||
|
||||
1. Create a GPT in the ChatGPT UI
|
||||
- Manually configure or use the GPT builder to create a GPT
|
||||
- Identify the API(s) you want to use
|
||||
2. Go to the "Configure" tab in the GPT editor and select "Create new action"
|
||||
- You will be presented with 3 main options: selecting the authentication schema for the action, inputting the schema itself, and setting the privacy policy URL
|
||||
- The Schema follows the OpenAPI specification format (not to be confused with OpenAI) to define how the GPT can access an external API
|
||||
3. Fill in the details for the schema, authentication, and privacy policy.
|
||||
- When selecting an authentication method, you will have 3 options, "None", "API Key", and "OAuth", we will explore these in depth later on
|
||||
- For the schema, you can take an existing OpenAPI specification you have for your API or create a new one. If you have already published an OpenAPI specification online, you can import it via the "Import from URL" button
|
||||
- The privacy policy URL is displayed to the user when they open a GPT and select the drop down in the top left corner showing the name of the GPT
|
||||
4. Determine the visibility of your GPT
|
||||
- By default, GPTs are not accessible to everyone
|
||||
- When you go to save a GPT, you will have the option to "Publish to" a certain audience: "Only me", "Anyone with a link", or "Everyone"
|
||||
- Each of these visibility options comes with different constraints and requirements. For example the naming of a GPT has more restrictions if you share it with someone else
|
||||
5. User(s) engage with your GPT
|
||||
- Depending on the visibility of your GPT, users might try it via a link you shared, or find it in the GPT store
|
||||
- If OAuth is required, users will be prompted to login during the session
|
||||
- Behind the scenes, the GPT injects the information on how you configured the GPT (including any available actions, tools, or instructions) into the context of the model
|
||||
- Each time a user makes a request, the model sees the available tools, actions, and instructions which determine how the GPT will respond to the request
|
||||
- If the user request is to check the weather in a specific location and you made a "Check weather" action available, the model will follow the OpenAPI specification you provided to send a request to that API and return the response to the user
|
||||
|
||||
[Next steps](https://platform.openai.com/docs/actions/introduction/next-steps)
|
||||
|
||||
Now that you know the basics of how a GPT works and where actions can be used, you might want to:
|
||||
|
||||
- Get started building a [GPT with an action](https://platform.openai.com/docs/actions/getting-started)
|
||||
- Learn how we [built the GPT builder](https://help.openai.com/en/articles/8770868-gpt-builder) itself as a custom GPT with actions
|
||||
- Familiarize yourself with our [GPT polices](https://openai.com/policies/usage-policies#:~:text=or educational purposes.-,Building with ChatGPT,-Shared GPTs allow)
|
||||
- Explore the [differences between GPTs and Assistants](https://help.openai.com/en/articles/8673914-gpts-vs-assistants)
|
||||
- Check out the [GPT data privacy FAQ's](https://help.openai.com/en/articles/8554402-gpts-data-privacy-faqs)
|
||||
- Find answers to [common GPT questions](https://help.openai.com/en/articles/8554407-gpts-faq)
|
||||
|
||||
## [Getting started](https://platform.openai.com/docs/actions/getting-started/getting-started)
|
||||
|
||||
Creating an action for a GPT takes 3 steps:
|
||||
|
||||
1. Build an API
|
||||
2. Document the API in the OpenAPI YAML or JSON format
|
||||
3. Expose the Schema to your GPT in the ChatGPT UI
|
||||
|
||||
The focus of the rest of this section will be creating a TODO list GPT by defining the custom action for the GPT.
|
||||
|
||||
If you want to kickstart the process of creating your GPT schema, you can use the [experimental ActionsGPT](https://chat.openai.com/g/g-TYEliDU6A-actionsgpt). Keep in mind the [known limitation when building a GPT](https://platform.openai.com/docs/actions/getting-started/limitations).
|
||||
|
||||
[Schema definition](https://platform.openai.com/docs/actions/getting-started/schema-definition)
|
||||
|
||||
Once you [create the basics](https://help.openai.com/en/articles/8554397-creating-a-gpt) of a TODO GPT, the next step is to build the [OpenAPI specification](https://swagger.io/specification/) to document the API. The model in ChatGPT is only aware of your API structure as defined in the schema. If your API is extensive, you don't need to expose all its functionality to the model; you can choose only specific endpoints to include. For example, if you have a social media API, you might want to have the model access content from the site through a GET request but prevent the model from being able to comment on users posts in order to reduce the chance of spam.
|
||||
|
||||
The OpenAPI specification is the wrapper that sits on top of your API. A basic OpenAPI specification will look like the following:
|
||||
|
||||
```text
|
||||
openapi: 3.0.1
|
||||
info:
|
||||
title: TODO Action
|
||||
description: An action that allows the user to create and manage a TODO list using a GPT.
|
||||
version: 'v1'
|
||||
servers:
|
||||
- url: https://example.com
|
||||
paths:
|
||||
/todos:
|
||||
get:
|
||||
operationId: getTodos
|
||||
summary: Get the list of todos
|
||||
responses:
|
||||
"200":
|
||||
description: OK
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: '#/components/schemas/getTodosResponse'
|
||||
components:
|
||||
schemas:
|
||||
getTodosResponse:
|
||||
type: object
|
||||
properties:
|
||||
todos:
|
||||
type: array
|
||||
items:
|
||||
type: string
|
||||
description: The list of todos.
|
||||
```
|
||||
|
||||
We start by defining the specification version, the title, description, and version number. When a query is run in ChatGPT, it will look at the description that is defined in the info section to determine if the action is relevant for the user query. You can read more about prompting in the [writing descriptions](https://platform.openai.com/docs/actions/getting-started/writing-descriptions) section.
|
||||
|
||||
Keep in mind the following limits in your OpenAPI specification, which are subject to change:
|
||||
|
||||
- 300 characters max for each API endpoint description/summary field in API specification
|
||||
- 700 characters max for each API parameter description field in API specification
|
||||
|
||||
The OpenAPI specification follows the traditional OpenAPI format, you can [learn more about OpenAPI formatting](https://swagger.io/tools/open-source/getting-started/) and how it works. There are also many tools that auto generate OpenAPI specifications based on your underlying API code.
|
||||
|
||||
[Hosted OpenAPI specification](https://platform.openai.com/docs/actions/getting-started/hosted-openapi-specification)
|
||||
|
||||
With Actions, we host the OpenAPI specification for your API in order to track changes. You can import an existing OpenAPI specification or create a new one from scratch using the [UI in the GPT creator](https://chat.openai.com/gpts/editor).
|
||||
|
||||
[Consequential flag](https://platform.openai.com/docs/actions/getting-started/consequential-flag)
|
||||
|
||||
In the OpenAPI specification, you can now set certain endpoints as "consequential" as shown below:
|
||||
|
||||
```text
|
||||
paths:
|
||||
/todo:
|
||||
get:
|
||||
operationId: getTODOs
|
||||
description: Fetches items in a TODO list from the API.
|
||||
security: []
|
||||
post:
|
||||
operationId: updateTODOs
|
||||
description: Mutates the TODO list.
|
||||
x-openai-isConsequential: true
|
||||
```
|
||||
|
||||
A good example of a consequential action is booking a hotel room and paying for it on behalf of a user.
|
||||
|
||||
- If the `x-openai-isConsequential` field is `true`, we treat the operation as "must always prompt the user for confirmation before running" and don't show an "always allow" button (both are features of GPTs designed to give builders and users more control over actions).
|
||||
- If the `x-openai-isConsequential` field is `false`, we show the "always allow button".
|
||||
- If the field isn't present, we default all GET operations to `false` and all other operations to `true`
|
||||
|
||||
[Multiple authentication schemas](https://platform.openai.com/docs/actions/getting-started/multiple-authentication-schemas)
|
||||
|
||||
When defining an action, you can mix a single authentication type (OAuth or API key) along with endpoints that do not require authentication.
|
||||
|
||||
You can learn more about action authentication on our [actions authentication page](https://platform.openai.com/docs/actions/authentication).
|
||||
|
||||
[Testing an action](https://platform.openai.com/docs/actions/getting-started/testing-an-action)
|
||||
|
||||
In the GPT editor, once you have added an action, a new section below the schema will appear called "Available actions", this is generated by parsing the schema. You can preview the name, method, and path the action lives at. There will also be a "Test" button displayed which allows you to try your actions. After you press "Test", in the preview section of the GPT editor you will be presented with a request to "Allow", "Always allow", or "Decline" to run the action. These are user confirmations designed to given end users more control over what an action does.
|
||||
|
||||
There are also various debugging information made available inside the preview mode which should help you understand any unintended behavior. If everything is working as expected, you can save or update your GPT in the top right corner.
|
||||
|
||||
[Writing descriptions](https://platform.openai.com/docs/actions/getting-started/writing-descriptions)
|
||||
|
||||
When a user makes a query that might trigger an action, the model looks through the descriptions of the endpoints in the schema. Just like with prompting other language models, you will want to test out multiple prompts and descriptions to see what works best.
|
||||
|
||||
The schema is a great place to provide the model with detailed information about your API, such as the available functions and their parameters. Besides using expressive, informative names for each field, the schema can also contain "description" fields for every attribute. You can use these fields to provide natural language descriptions that explain what each method does or what information a query field requires. The model will be able to see these, and they will guide it in using the API. If a field is restricted to only certain values, you can also provide an "enum" with descriptive category names.
|
||||
|
||||
The instructions for a GPT gives you the freedom to instruct the GPT on how to use your action generally. Overall, the language model behind ChatGPT is highly capable of understanding natural language and following instructions. Therefore, this is a good place to put in general instructions on what your action does and how the GPT should use it properly. Use natural language, preferably in a concise yet descriptive and objective tone. You can look at some of the examples to have an idea of what this should look like.
|
||||
|
||||
[Best practices](https://platform.openai.com/docs/actions/getting-started/best-practices)
|
||||
|
||||
Here are some best practices to follow when writing your GPT instructions and descriptions in your schema, as well as when designing your API responses:
|
||||
|
||||
1. Your descriptions should not encourage the GPT to use the action when the user hasn't asked for your action's particular category of service.
|
||||
|
||||
*Bad example*:
|
||||
|
||||
> Whenever the user mentions any type of task, ask if they would like to use the TODO action to add something to their todo list.
|
||||
|
||||
*Good example*:
|
||||
|
||||
> The TODO list can add, remove and view the user's TODOs.
|
||||
|
||||
2. Your descriptions should not prescribe specific triggers for the GPT to use the action. ChatGPT is designed to use your action automatically when appropriate.
|
||||
|
||||
*Bad example*:
|
||||
|
||||
> When the user mentions a task, respond with "Would you like me to add this to your TODO list? Say 'yes' to continue."
|
||||
|
||||
*Good example*:
|
||||
|
||||
> [no instructions needed for this]
|
||||
|
||||
3. Action responses from an API should return raw data instead of natural language responses unless it's necessary. The GPT will provide its own natural language response using the returned data.
|
||||
|
||||
*Bad example*:
|
||||
|
||||
> I was able to find your todo list! You have 2 todos: get groceries and walk the dog. I can add more todos if you'd like!
|
||||
|
||||
*Good example*:
|
||||
|
||||
> { "todos": [ "get groceries", "walk the dog" ] }
|
||||
|
||||
[Limitations](https://platform.openai.com/docs/actions/getting-started/limitations)
|
||||
|
||||
There are a few limitations to be aware of when building with actions:
|
||||
|
||||
- Custom headers are not supported
|
||||
- With the exception of Google, Microsoft and Adobe OAuth domains, all domains used in an OAuth flow must be the same as the domain used for the primary endpoints
|
||||
- Request and response payloads must be less than 100,000 characters each
|
||||
- Requests timeout after 45 seconds
|
||||
- Requests and responses can only contain text (no images or video)
|
||||
|
||||
If you have questions or run into additional limitations, you can join the discussion on the [OpenAI developer forum](https://community.openai.com/).
|
||||
|
||||
## [Action authentication](https://platform.openai.com/docs/actions/authentication/action-authentication)
|
||||
|
||||
Actions offer different authentication schemas to accommodate various use cases. To specify the authentication schema for your action, use the GPT editor and select "None", "API Key", or "OAuth".
|
||||
|
||||
By default, the authentication method for all actions is set to "None", but you can change this and allow different actions to have different authentication methods.
|
||||
|
||||
[No authentication](https://platform.openai.com/docs/actions/authentication/no-authentication)
|
||||
|
||||
We support flows without authentication for applications where users can send requests directly to your API without needing an API key or signing in with OAuth.
|
||||
|
||||
Consider using no authentication for initial user interactions as you might experience a user drop off if they are forced to sign into an application. You can create a "signed out" experience and then move users to a "signed in" experience by enabling a separate action.
|
||||
|
||||
[API key authentication](https://platform.openai.com/docs/actions/authentication/api-key-authentication)
|
||||
|
||||
Just like how a user might already be using your API, we allow API key authentication through the GPT editor UI. We encrypt the secret key when we store it in our database to keep your API key secure.
|
||||
|
||||
This approach is useful if you have an API that takes slightly more consequential actions than the no authentication flow but does not require an individual user to sign in. Adding API key authentication can protect your API and give you more fine-grained access controls along with visibility into where requests are coming from.
|
||||
|
||||
[OAuth](https://platform.openai.com/docs/actions/authentication/oauth)
|
||||
|
||||
Actions allow OAuth sign in for each user. This is the best way to provide personalized experiences and make the most powerful actions available to users. A simple example of the OAuth flow with actions will look like the following:
|
||||
|
||||
- To start, select "Authentication" in the GPT editor UI, and select "OAuth".
|
||||
- You will be prompted to enter the OAuth client ID, client secret, authorization URL, token URL, and scope.
|
||||
- The client ID and secret can be simple text strings but should [follow OAuth best practices](https://www.oauth.com/oauth2-servers/client-registration/client-id-secret/).
|
||||
- We store an encrypted version of the client secret, while the client ID is available to end users.
|
||||
- OAuth requests will include the following information: `request={'grant_type': 'authorization_code', 'client_id': 'YOUR_CLIENT_ID', 'client_secret': 'YOUR_CLIENT_SECRET', 'code': 'abc123', 'redirect_uri': 'https://chat.openai.com/aip/g-some_gpt_id/oauth/callback'}`
|
||||
- In order for someone to use an action with OAuth, they will need to send a message that invokes the action and then the user will be presented with a "Sign in to [domain]" button in the ChatGPT UI.
|
||||
- The `authorization_url` endpoint should return a response that looks like: `{ "access_token": "example_token", "token_type": "bearer", "refresh_token": "example_token", "expires_in": 59 }`
|
||||
- During the user sign in process, ChatGPT makes a request to your `authorization_url` using the specified `authorization_content_type`, we expect to get back an access token and optionally a [refresh token](https://auth0.com/learn/refresh-tokens) which we use to periodically fetch a new access token.
|
||||
- Each time a user makes a request to the action, the user’s token will be passed in the Authorization header: (“Authorization”: “[Bearer/Basic][user’s token]”).
|
||||
- We require that OAuth applications make use of the [state parameter](https://auth0.com/docs/secure/attack-protection/state-parameters#set-and-compare-state-parameter-values) for security reasons.
|
||||
|
||||
## [Data retrieval with GPT Actions](https://platform.openai.com/docs/actions/data-retrieval/data-retrieval-with-gpt-actions)
|
||||
|
||||
One of the most common tasks an action in a GPT can perform is data retrieval. An action might:
|
||||
|
||||
1. Access an API to retrieve data based on a keyword search
|
||||
2. Access a relational database to retrieve records based on a structured query
|
||||
3. Access a vector database to retrieve text chunks based on semantic search
|
||||
|
||||
We’ll explore considerations specific to the various types of retrieval integrations in this guide.
|
||||
|
||||
[Data retrieval using APIs](https://platform.openai.com/docs/actions/data-retrieval/data-retrieval-using-apis)
|
||||
|
||||
Many organizations rely on 3rd party software to store important data. Think Salesforce for customer data, Zendesk for support data, Confluence for internal process data, and Google Drive for business documents. These providers often provide REST APIs which enable external systems to search for and retrieve information.
|
||||
|
||||
When building an action to integrate with a provider's REST API, start by reviewing the existing documentation. You’ll need to confirm a few things:
|
||||
|
||||
1. Retrieval methods
|
||||
|
||||
- **Search** - Each provider will support different search semantics, but generally you want a method which takes a keyword or query string and returns a list of matching documents. See [Google Drive’s `file.list` method](https://developers.google.com/drive/api/guides/search-files) for an example.
|
||||
- **Get** - Once you’ve found matching documents, you need a way to retrieve them. See [Google Drive’s `file.get` method](https://developers.google.com/drive/api/reference/rest/v3/files/get) for an example.
|
||||
|
||||
2. Authentication scheme
|
||||
|
||||
- For example, [Google Drive uses OAuth](https://developers.google.com/workspace/guides/configure-oauth-consent) to authenticate users and ensure that only their available files are available for retrieval.
|
||||
|
||||
3. OpenAPI spec
|
||||
|
||||
- Some providers will provide an OpenAPI spec document which you can import directly into your action. See
|
||||
|
||||
|
||||
|
||||
Zendesk
|
||||
|
||||
, for an example.
|
||||
|
||||
- You may want to remove references to methods your GPT *won’t* access, which constrains the actions your GPT can perform.
|
||||
|
||||
- For providers who *don’t* provide an OpenAPI spec document, you can create your own using the [ActionsGPT](https://chat.openai.com/g/g-TYEliDU6A-actionsgpt) (a GPT developed by OpenAI).
|
||||
|
||||
Your goal is to get the GPT to use the action to search for and retrieve documents containing context which are relevant to the user’s prompt. Your GPT follows your instructions to use the provided search and get methods to achieve this goal.
|
||||
|
||||
[Data retrieval using Relational Databases](https://platform.openai.com/docs/actions/data-retrieval/data-retrieval-using-relational-databases)
|
||||
|
||||
Organizations use relational databases to store a variety of records pertaining to their business. These records can contain useful context that will help improve your GPT’s responses. For example, let’s say you are building a GPT to help users understand the status of an insurance claim. If the GPT can look up claims in a relational database based on a claims number, the GPT will be much more useful to the user.
|
||||
|
||||
When building an action to integrate with a relational database, there are a few things to keep in mind:
|
||||
|
||||
1. Availability of REST APIs
|
||||
- Many relational databases do not natively expose a REST API for processing queries. In that case, you may need to build or buy middleware which can sit between your GPT and the database.
|
||||
- This middleware should do the following:
|
||||
- Accept a formal query string
|
||||
- Pass the query string to the database
|
||||
- Respond back to the requester with the returned records
|
||||
2. Accessibility from the public internet
|
||||
- Unlike APIs which are designed to be accessed from the public internet, relational databases are traditionally designed to be used within an organization’s application infrastructure. Because GPTs are hosted on OpenAI’s infrastructure, you’ll need to make sure that any APIs you expose are accessible outside of your firewall.
|
||||
3. Complex query strings
|
||||
- Relational databases uses formal query syntax like SQL to retrieve relevant records. This means that you need to provide additional instructions to the GPT indicating which query syntax is supported. The good news is that GPTs are usually very good at generating formal queries based on user input.
|
||||
4. Database permissions
|
||||
- Although databases support user-level permissions, it is likely that your end users won’t have permission to access the database directly. If you opt to use a service account to provide access, consider giving the service account read-only permissions. This can avoid inadvertently overwriting or deleting existing data.
|
||||
|
||||
Your goal is to get the GPT to write a formal query related to the user’s prompt, submit the query via the action, and then use the returned records to augment the response.
|
||||
|
||||
[Data retrieval using Vector Databases](https://platform.openai.com/docs/actions/data-retrieval/data-retrieval-using-vector-databases)
|
||||
|
||||
If you want to equip your GPT with the most relevant search results, you might consider integrating your GPT with a vector database which supports semantic search as described above. There are many managed and self hosted solutions available on the market, [see here for a partial list](https://github.com/openai/chatgpt-retrieval-plugin#choosing-a-vector-database).
|
||||
|
||||
When building an action to integrate with a vector database, there are a few things to keep in mind:
|
||||
|
||||
1. Availability of REST APIs
|
||||
- Many relational databases do not natively expose a REST API for processing queries. In that case, you may need to build or buy middleware which can sit between your GPT and the database (more on middleware below).
|
||||
2. Accessibility from the public internet
|
||||
- Unlike APIs which are designed to be accessed from the public internet, relational databases are traditionally designed to be used within an organization’s application infrastructure. Because GPTs are hosted on OpenAI’s infrastructure, you’ll need to make sure that any APIs you expose are accessible outside of your firewall.
|
||||
3. Query embedding
|
||||
- As discussed above, vector databases typically accept a vector embedding (as opposed to plain text) as query input. This means that you need to use an embedding API to convert the query input into a vector embedding before you can submit it to the vector database. This conversion is best handled in the REST API gateway, so that the GPT can submit a plaintext query string.
|
||||
4. Database permissions
|
||||
- Because vector databases store text chunks as opposed to full documents, it can be difficult to maintain user permissions which might have existed on the original source documents. Remember that any user who can access your GPT will have access to all of the text chunks in the database and plan accordingly.
|
||||
|
||||
[Middleware for vector databases](https://platform.openai.com/docs/actions/data-retrieval/middleware-for-vector-databases)
|
||||
|
||||
As described above, middleware for vector databases typically needs to do two things:
|
||||
|
||||
1. Expose access to the vector database via a REST API
|
||||
2. Convert plaintext query strings into vector embeddings
|
||||
|
||||
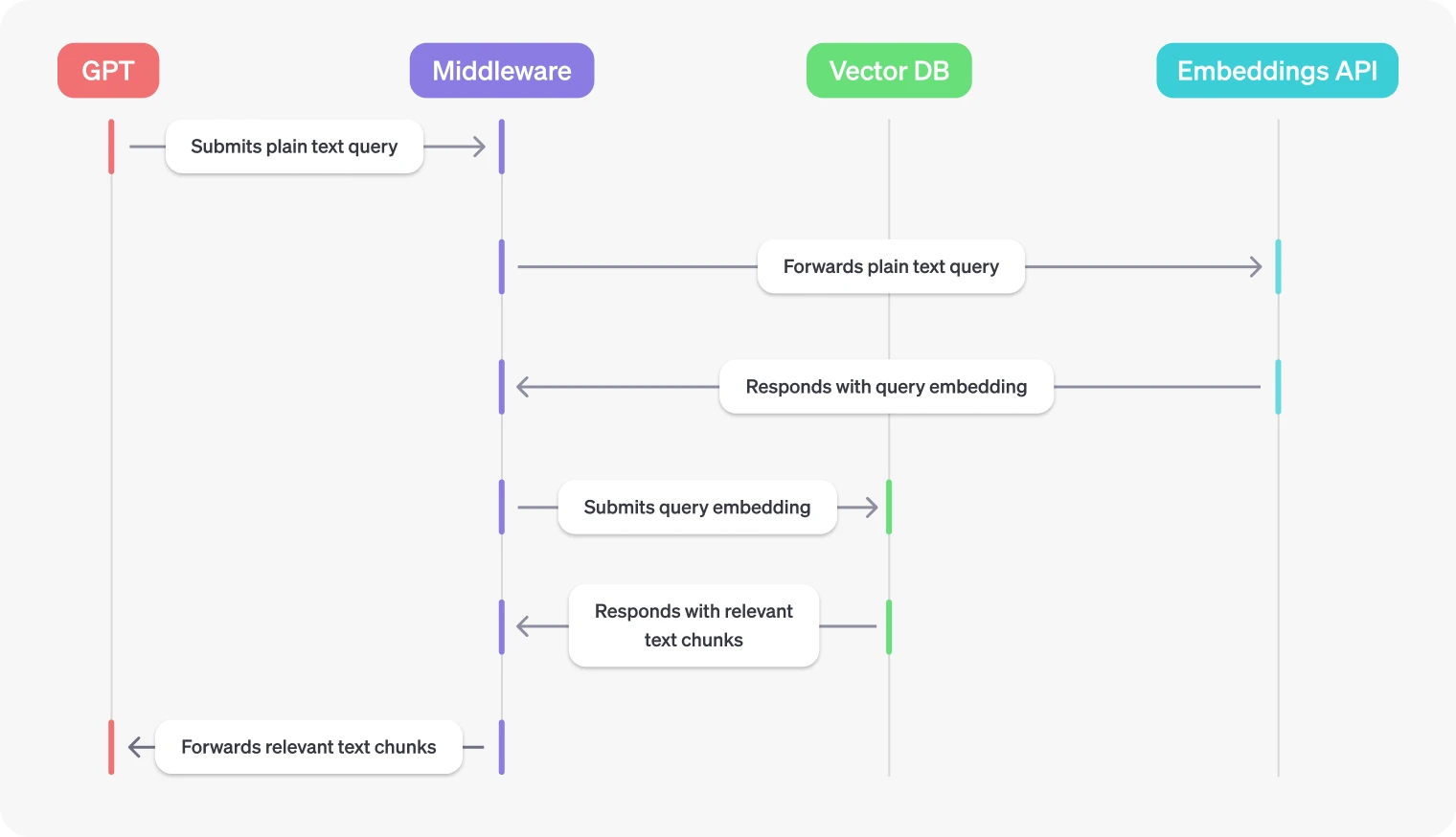
|
||||
|
||||
The goal is to get your GPT to submit a relevant query to a vector database to trigger a semantic search, and then use the returned text chunks to augment the response.
|
||||
|
||||
## Building with ChatGPT
|
||||
|
||||
https://openai.com/policies/usage-policies
|
||||
|
||||
Shared GPTs allow you to use ChatGPT to build experiences for others. Because your GPT’s users are also OpenAI users, when building with ChatGPT, we have the following service-specific policies in addition to our Universal Policies:
|
||||
|
||||
1. Don’t compromise the privacy of others, including:
|
||||
- a. Collecting, processing, disclosing, inferring or generating personal data without complying with applicable legal requirements
|
||||
- b. Soliciting or collecting the following sensitive identifiers, security information, or their equivalents: payment card information (e.g. credit card numbers or bank account information), government identifiers (e.g. SSNs), API keys, or passwords
|
||||
- c. Using biometric identification systems for identification or assessment, including facial recognition
|
||||
- d. Facilitating spyware, communications surveillance, or unauthorized monitoring of individuals
|
||||
2. Don’t perform or facilitate the following activities that may significantly affect the safety, wellbeing, or rights of others, including:
|
||||
- a. Taking unauthorized actions on behalf of users
|
||||
- b. Providing tailored legal, medical/health, or financial advice
|
||||
- c. Making automated decisions in domains that affect an individual’s rights or well-being (e.g., law enforcement, migration, management of critical infrastructure, safety components of products, essential services, credit, employment, housing, education, social scoring, or insurance)
|
||||
- d. Facilitating real money gambling or payday lending
|
||||
- e. Engaging in political campaigning or lobbying, including generating campaign materials personalized to or targeted at specific demographics
|
||||
- f. Deterring people from participation in democratic processes, including misrepresenting voting processes or qualifications and discouraging voting
|
||||
3. Don’t misinform, misrepresent, or mislead others, including:
|
||||
- a. Generating or promoting disinformation, misinformation, or false online engagement (e.g., comments, reviews)
|
||||
- b. Impersonating another individual or organization without consent or legal right
|
||||
- c. Engaging in or promoting academic dishonesty
|
||||
- d. Using content from third parties without the necessary permissions
|
||||
- e. Misrepresenting or misleading others about the purpose of your GPT
|
||||
4. Don’t build tools that may be inappropriate for minors, including:
|
||||
- a. Sexually explicit or suggestive content. This does not include content created for scientific or educational purposes.
|
||||
5. Don’t build tools that target users under 13 years of age.
|
||||
|
||||
We use a combination of automated systems, human review, and user reports to find and assess GPTs that potentially violate our policies. Violations can lead to actions against the content or your account, such as warnings, sharing restrictions, or ineligibility for inclusion in GPT Store or monetization.
|
||||
Reference in New Issue
Block a user